
Python sklearn 做线性回归预测
2024-12-26
学到老活到老,本来作为一个码农,从来都不想接触的就是深度学习相关,因为真的很累,而且花大量时间,但是最近有了一些些想法,所以开始学习了,记录一些我的笔记供大家参考!
1. 数据集获取
通过网盘分享的文件:data.csv 链接: https://pan.baidu.com/s/1fpU39J-5MsUB0JIuYpzlmw?pwd=yuer 提取码: yuer
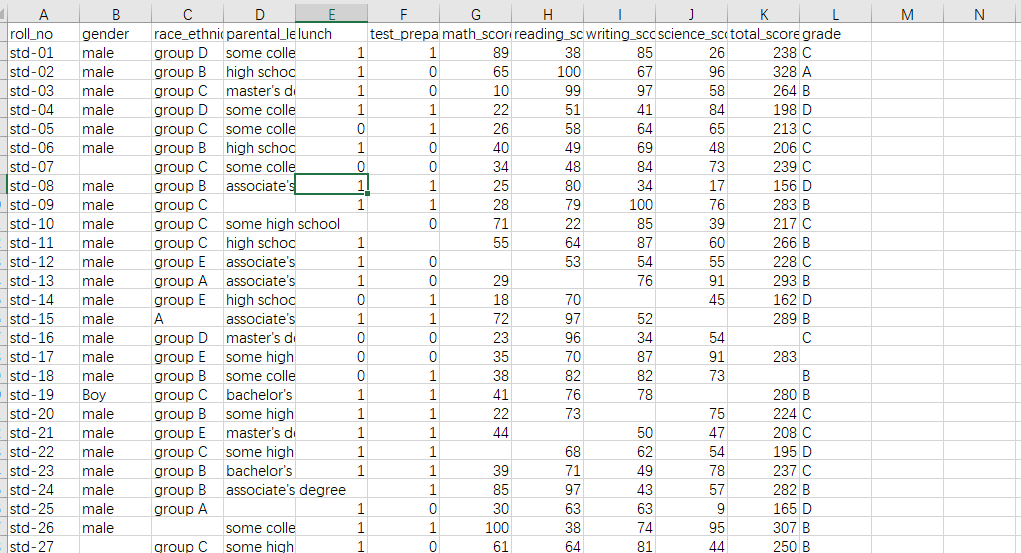
数据集是一个csv格式的文件,可以打开预览一下,具体怎么看数据集就不用我教了吧
2.环境配置
pip install pandas pip install sklearn pip install joblib
3.问题分析
数据集打开可以看到reading_score和 writing_score,阅读分数和写作分数,现实生活中读和写相关性就比较高,因此我们可以做读和写的线性预测,通过一个人的reading_score去预测他的writing_score,而这个时候reading_score就被称作为特征向量或者特征变量,writing_score就被称作为目标向量或者目标变量
4.代码编写
4.1库的导入
import pandas as pd from sklearn.model_selection import train_test_split from sklearn.linear_model import LinearRegression # 线性回归模型 from sklearn.metrics import mean_squared_error, r2_score from sklearn.preprocessing import LabelEncoder
4.2数据导入
data = pd.read_csv('data.csv')4.3清洗数据
先说一下为什么要清洗数据,原因很简单,因为我们的数据集经常会出现读取错误,以该项目为例,如果有考生缺考,那么他的成绩就应该为空,那么读取的时候就会出错,或者老师在填写数据表的时候因为粗心打字错误之类的导致python读取数据的时候无法读取,所以我们需要对这些数据进行清洗
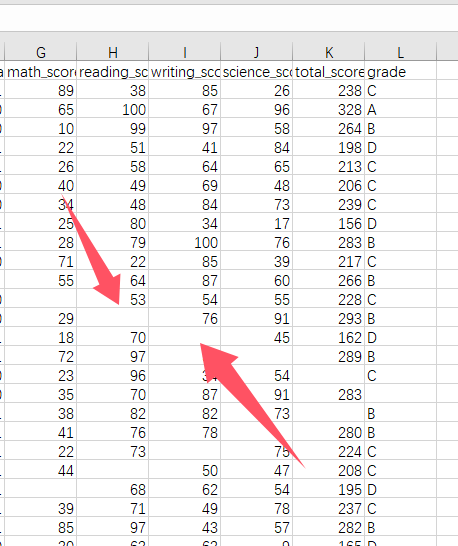
那我说一下我对于本次项目数据清洗的流程,首先将所有单元格的数据去除前后空格和制表符,然后转换为数字,无法转换的值会变为NaN,然后再对于Nan以及空的值进行删除
data['reading_score'] = data['reading_score'].apply(lambda x: str(x).strip()) # 去除前后空格和制表符 data['writing_score'] = data['writing_score'].apply(lambda x: str(x).strip()) data['reading_score'] = pd.to_numeric(data['reading_score'], errors='coerce') # 转换为数字,无法转换的值会变为NaN data['writing_score'] = pd.to_numeric(data['writing_score'], errors='coerce') data = data.dropna(subset=['reading_score', 'writing_score']) # 删除阅读成绩和写作成绩为空的数据
4.4定义特征变量和目标变量
# 特征变量 (reading_score) X = data[['reading_score']] # 目标变量 (total_score) y = data['writing_score']
4.5划分测试集和训练集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
各个参数的解释,偷个懒,用gpt的解释给大家看

4.6模型选择和开始训练
值得解释的是,这个项目就比较适合线性回归,线性回归一般适合于,x、y都是线性变化,比如说性别就是种类值,不是线性变化,线性变化可以是某一个区间的任意值,比如成绩可以是1-100的任意值,这种一般用线性回归就比较好,其他模型大家可以自行百度进行学习,这里不做赘述
# 初始化线性回归模型 model = LinearRegression() # 训练模型 model.fit(X_train, y_train)
4.7对模型的结果进行观测
模型训练了总得要有一个东西来看看效果怎么样对吧,这个时候我们刚才划分的测试集就用得上了
# 预测测试集
y_pred = model.predict(X_test)
# 评估模型
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
# 输出评估结果
print(f'Mean Squared Error: {mse}')
print(f'R-squared: {r2}')mse 和 r2 是什么


mse和r2看得懂肯定是最好的,但是看不懂也没关系

4.8结果分析

4.9具体预测某个值
模型训练好了就是要用来用的,我想具体预测某一个值应该如何编写代码呢
# 预测一个新的 reading_score 对应的 writing_score
new_reading_score = [[85]] # 新的 reading_score 值,注意需要是二维数组
predicted_writing_score = model.predict(new_reading_score)
print(f'Predicted writing score for reading score 85: {predicted_writing_score[0]}')运行测试
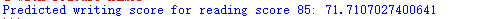
4.10模型保存
import joblib # 保存训练好的模型 joblib.dump(model, 'linear_regression_model.pkl')
至此模型的代码均已写完
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression # 线性回归模型
from sklearn.metrics import mean_squared_error, r2_score
from sklearn.preprocessing import LabelEncoder
import joblib
# 加载数据集
data = pd.read_csv('data.csv')
# 清洗数据:去除前后空格和制表符,并将成绩列转换为数字
data['reading_score'] = data['reading_score'].apply(lambda x: str(x).strip()) # 去除前后空格和制表符
data['writing_score'] = data['writing_score'].apply(lambda x: str(x).strip())
data['reading_score'] = pd.to_numeric(data['reading_score'], errors='coerce') # 转换为数字,无法转换的值会变为NaN
data['writing_score'] = pd.to_numeric(data['writing_score'], errors='coerce')
data = data.dropna(subset=['reading_score', 'writing_score']) # 删除阅读成绩和写作成绩为空的数据
# 特征变量 (reading_score)
X = data[['reading_score']]
# 目标变量 (writing_score)
y = data['writing_score']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 初始化线性回归模型
model = LinearRegression()
# 训练模型
model.fit(X_train, y_train)
# 预测测试集
y_pred = model.predict(X_test)
# 评估模型
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
# 输出评估结果
print(f'Mean Squared Error: {mse}')
print(f'R-squared: {r2}')
# 保存训练好的模型
joblib.dump(model, 'linear_regression_model.pkl')代码运行以后桌面会生成一个pkl文件就是模型了
4.11模型调用
import joblib
# 加载模型
model = joblib.load('linear_regression_model.pkl')
# 使用加载的模型进行预测
new_reading_score = [[85]] # 新的 reading_score 值,注意需要是二维数组
predicted_writing_score = model.predict(new_reading_score)
print(f'Predicted writing score for reading score 85: {predicted_writing_score[0]}')5.完结撒花
学到老,活到老!
发表评论: